
»Specificity« is one of the most important (and unsettling?) concepts to understand when writing CSS. It’s a weight applied to a given CSS declaration by which browsers decide which property values are the most relevant to an element and, therefore, will be used. While there are already lots of articles and tools regarding specificity and how to beat it, I always wondered about the emerging »complexity«, the resulting decrease in CSS rendering performance, and the impact on the code quality in general.
But: First things first.
An introduction to CSS selectors
In short, browsers construct a tree structure out of HTML elements, match CSS selectors against them, apply those styles, and finally render the document to the screen. Every CSS rule-set consists of individual (or joint) selectors followed by a declaration block consisting of style properties and their values.
#sidebar .contact p {
background: red;
}
This joint selector matches any <p> element that is a descendant of any kind of element with a class attribute that contains the word contact that is a descendant of any kind of element with an ID attribute that equals sidebar itself. The following HTML fragment is an example of a match for this selector.
<div id="sidebar">
<div class="contact">
<p>Lorem ipsum dolor sit amet</p>
</div>
</div>
Specificity of CSS selectors
In case multiple property declarations are defined for an element, browsers have to find the »winning« declaration, meaning its value will be applied for the respective CSS property. The following example shows two declarations for the background of HTML paragraph elements.
#sidebar .contact p {
background: red;
}
p {
margin-bottom: 1em;
background: blue;
}
You might think that blue wins because it overwrites the previous style due to the order of appearance of the rule-sets. Or you might think that red is applied because its selector is much more specific. In order to determine the proper declaration, browser apply the following cascade of criteria.
- The weight as defined by the declaration’s origin stylesheet and the declaration’s importance (i.e. whether or not it’s declared
!important) - The specificity of its selector
- The order of appearance (i.e. the last declaration wins)
Speaking of »specificity«, you might wonder how a selector’s specificity is defined/calculated. Actually, it’s pretty easy.
- A = amount of ID selectors (e.g.
#sidebar) - B = amount of class selectors, attribute selectors, and pseudo-classes (e.g.
.contact/:hover) - C = amount of element selectors and pseudo-elements (e.g.
p/:before)
The concatenation of A, B, and C represents the specificity of the selector.
Selector Specificity = A,B,C
This implies that a single ID overrules a thousand classes as (unlike the decimal system) there is no carryover, meaning 1,0,0 doesn’t equal to 0,10,0 and is still more specific than 0,11,0. Note that inline styles (i.e. style information set by an element’s style attribute) are ignored within this analysis but have a specificity higher than any selector. Pseudo-classes such as :nth-child(odd) count like regular classes within this calculation while being much more specific with regard to the structure they represent.
The following snippet demonstrates this calculation based on the aforementioned example.
/*
One ID, one class, one element
A = 1, B = 1, C = 1
Specificity = 1,1,1
*/
#sidebar .contact p {
background: red;
}
/*
One element
A = 0, B = 0, C = 1
Specificity = 0,0,1
*/
p {
margin-bottom: 1em;
background: blue;
}
As a consequence, browsers render matching paragraphs with a red background and a bottom spacing of 1em. In this case, with respect to the p property, the specificity wins over the order of appearance. It’s important to note that the margin-bottom property of the second rule applies as there is no competing declaration within the more specific rule-set.
Complexity of CSS selectors due to specificity
While sophisticated selectors consisting of multifaceted combinations of elements, classes, and IDs simply reflect complex product requirements most of the time, they accelerate the overall stylesheet complexity and thus development costs while causing several drawbacks.
- Complex selectors are difficult to understand, modify, or maintain.
- Complex selectors lead to subsequent selectors of same or even higher specificity (to prevent overwriting).
- Complex selectors match special HTML fragments only (decreasing the reusability of code patterns).
The following code example is a selector taken par for par from the website of a news magazine, demonstrating a boost of code complexity due to extensive selectors.
.column-wide .asset-list-box-hp-special ul li div.video-pic div.image-buttons-panel a span.button.btn-video-text,
.column-wide .asset-list-box-centerteaser ul li div.video-pic div.image-buttons-panel a span.button.btn-video-text {
overflow: hidden;
height: 20px;
width: 15px;
line-height: 35px;
}
In case the corresponding HTML structure for this selectors have to be altered due to changing requirements, developers need to perform microsurgery, hoping that nothing will break without notice in other parts of the site/application.
In large projects with plenty of rule-sets, changes within the HTML pretty much never do not adversely affect CSS, making changes to HTML fragments unintentionally expensive. Furthermore selectors are formulated unnecessarily verbose a lot of times, specifying much more than actually required regarding the matching HTML fragments and their nesting. CSS pre-processors like SCSS/Sass, LESS, or Stylus boost the formation of such selectors as developers lose the connection between nesting within the tidy source code and the resulting selectors within the compiled CSS. It’s very likely that this was the reason for the aforementioned selector to emerge.
Measuring CSS selector complexity
While a simple formula for calculating/measuring the »specificity« of a CSS selector was presented above, there doesn’t exist some kind of general metric for calculating/defining the »complexity« of CSS selectors. In general, »metrics« are used to measure the quality of software and code. The IEEE defines a software metric more specific as follows[1].
A function whose inputs are software data and whose output is a single numerical value that can be interpreted as the degree to which software possesses a given attribute that affects its quality.
Since quantitative measurements are essential in all kind of sciences, there is a continuous effort by computer scientists to bring similar approaches to software development. The goal is to obtain objective, reproducible, and quantifiable measurements in order to support planning and estimations regarding budgets, costs, quality, debugging, or optimizations.
In my humble opinion the following two citations describe the general way of thinking about metrics and measurements, meaning they are pertinent and a precious aid but shall not be taken literally by force.
Not everything that can be counted counts. Not everything that counts can be counted.
You can‘t control what you can‘t measure.
As mentioned before, complex selectors are difficult to understand, modify, or maintain from the human perspective. However, another important aspect of developing CSS is how browsers read and interpret CSS (and how much time this step takes).
In general, browsers read CSS lines from right to left. This means that the engine evaluates each rule starting from the rightmost selector and moving through each selector until it finds a match or discards the rule.
#sidebar .contact p {
background: red;
}
Looking at the (familiar) example above, the browser first searches for the all the p tags on the page and then looks if the p tag has a parent with the class name contact and whether that parent has a parent with the identifier sidebar. Therefore complex (= long) selectors take up more time to be read and interpreted compared to short selectors.
Criteria for good complexity metrics
After applying a variety of complexity metrics to other programming languages in the past, I asked myself whether it’s possible to apply those metrics to CSS as well. In order to find and use proper metrics, they are supposed to comply with the following criteria for being applicable.
- Objectivity (no subjective influence)
- Reliability (same result when applied multiple times)
- Scaling (there’s a scale for measuring the results)
- Comparability (measurements can be compared)
- Economic Efficiency (taking measurements has low costs)
- Usefulness (measurements fulfill practical neeeds)
- Validity (measurements allow conclusions)
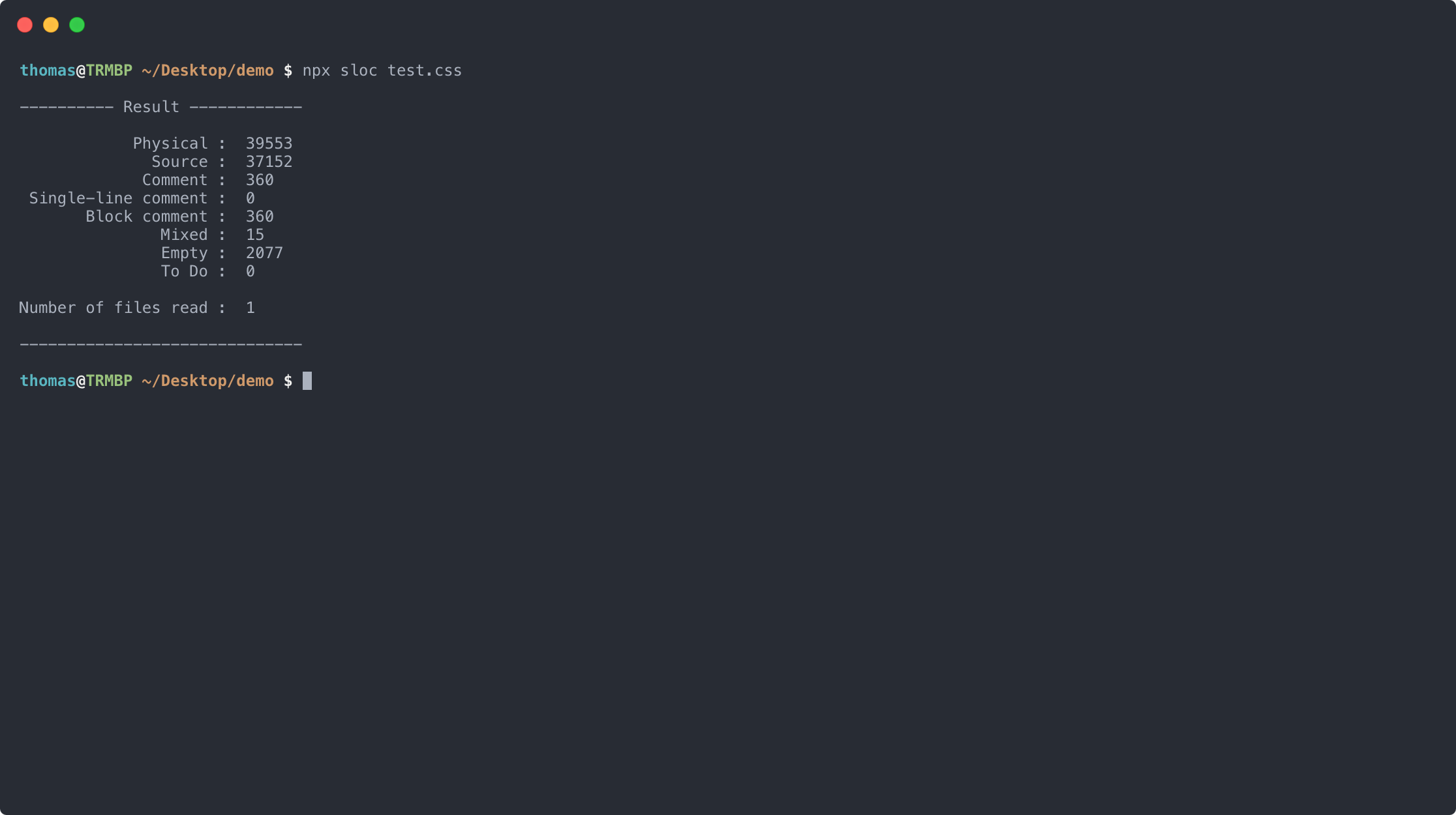
To give you an example of a metric: »Lines Of Code« (»LOC«) is (probably) the oldest and most widely used software metric. It measures the size (and thus the complexity?) of a software by counting the different lines of code.
- Lines of »real« code
- Lines with comments (overall vs. single-line vs. block)
- Lines mixed up with source and comments
- Empty lines
However, regarding the criteria defined before, it’s a very simple but also very meaningless metric (concerning its usefulness and validity) that only gives you a (very) rough idea of the overall complexity of your code.
CSS Complexity & Performance Analyzers
I decided to take a look at existing complexity/performance tools for analyzing CSS. All tools surface some interesting numbers by providing seemingly obvious and simple data that allow valuable insights about CSS files if one knows what the numbers represent.
Parker
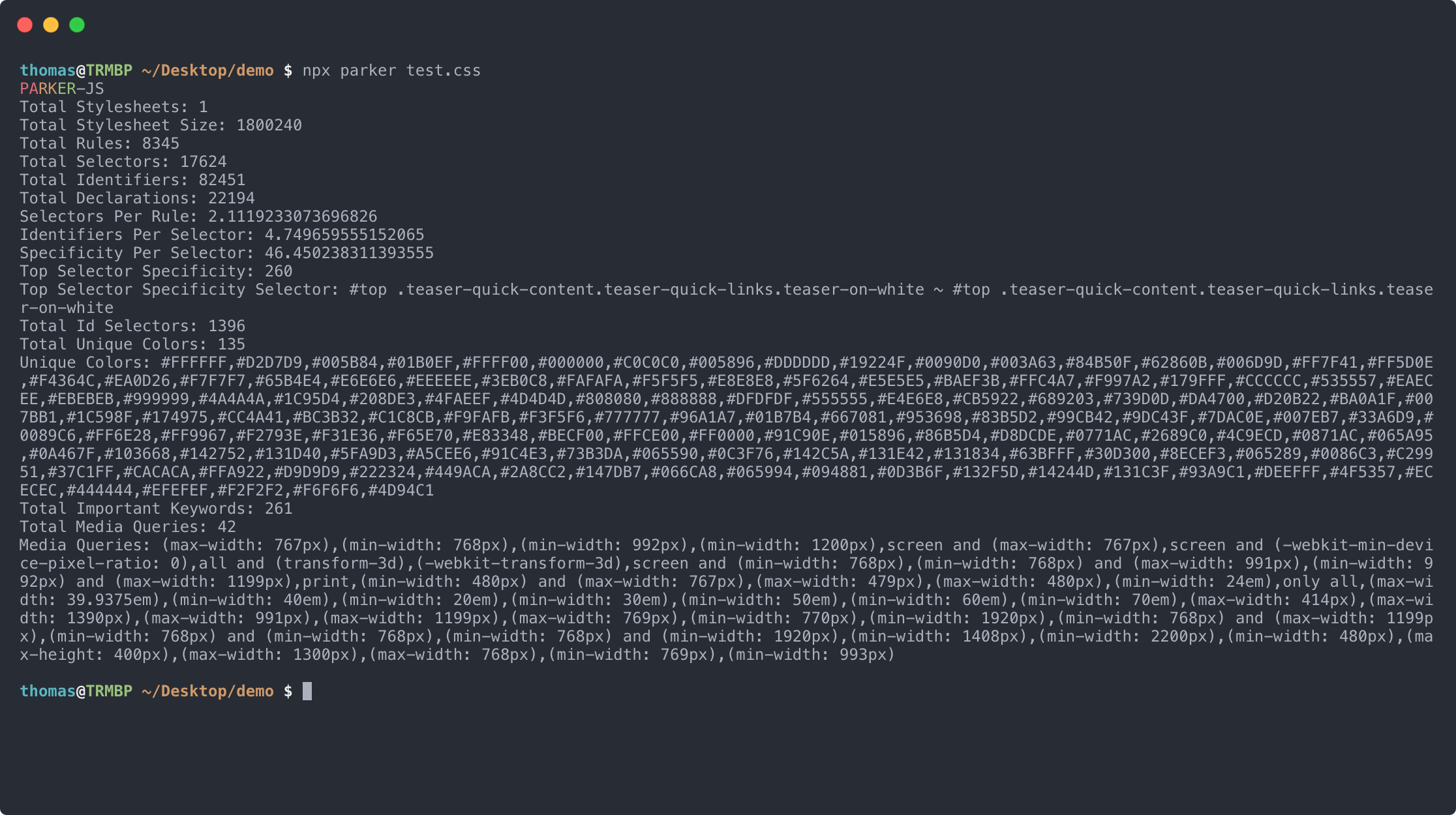
Parker is a simple static analysis tool that provides very insightful metrics about CSS files. Especially the following measurements tell you what your worst offenders are.
- Top Selector Specificity
- Top Selector Specificity Selector
- Total Important Keywords
analyze-css
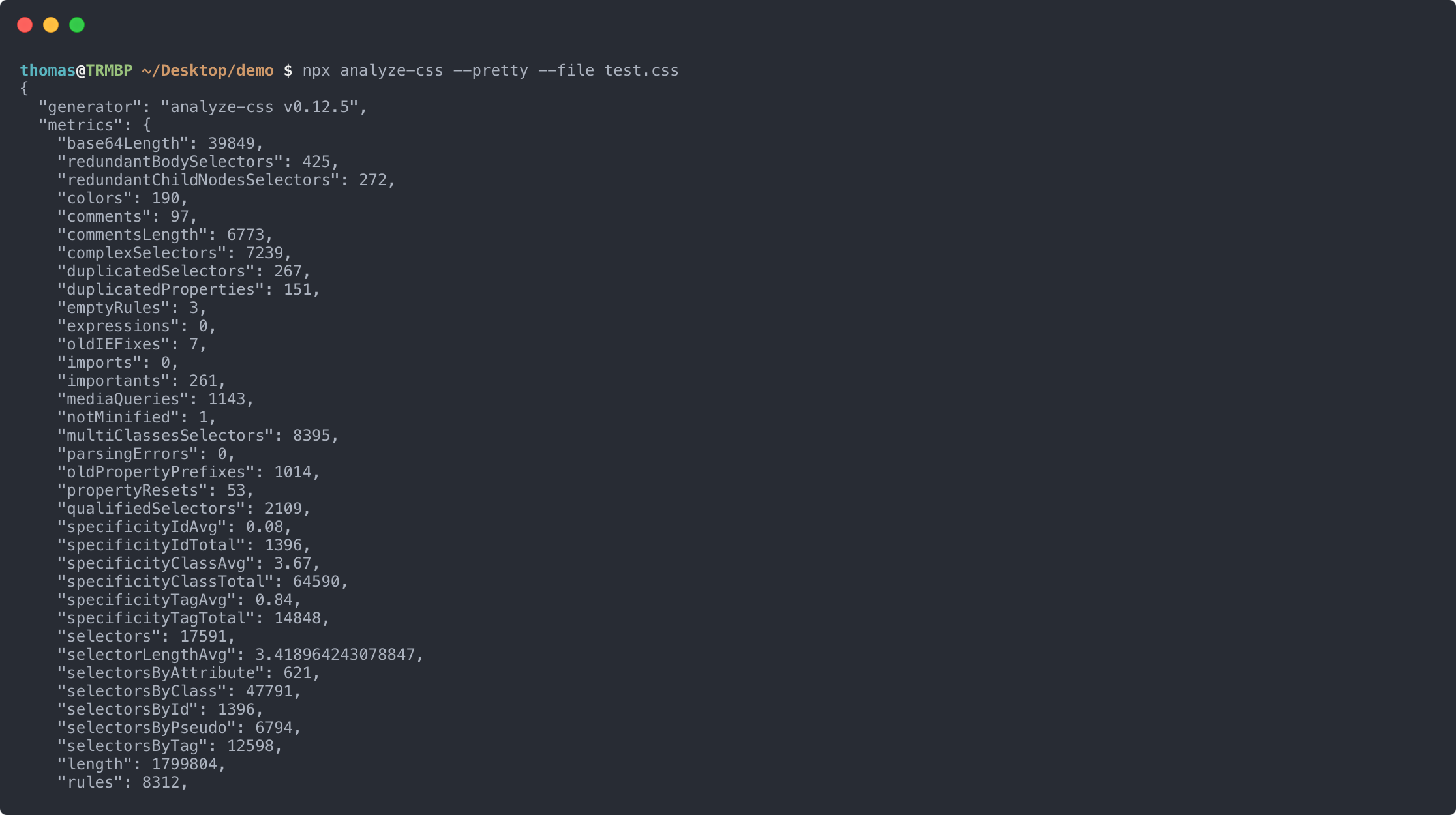
analyze-css is a complexity and performance analyzer providing several metrics. However, the metric that sparked my personal interest was complexSelectors. The tool itself defines this metric as follows[2].
complexSelectors: number of complex selectors (consisting of more than three expressions, e.g. header ul li .foo)
I wondered whether it’s possible to calculate a specific complexity for a given CSS selector and whether complexity really simply equals the amount of expressions. Therefore I decided to look into »cyclomatic complexity« (which I knew from other programming languages) in more detail.
Cyclomatic Complexity
»Cyclomatic complexity« is a software metric used to indicate the complexity of a program developed by Thomas J. McCabe in 1976.[3]
It’s a static source code complexity metric that is calculated by developing a control flow graph of the code. To be more specific, it’s a quantitative measure of the number of linearly independent paths through a program’s source code. »Independent paths« are defined as paths that have at least one edge which hasn’t been traversed before in any other paths. Control flow depicts a program as a graph which consists of nodes and edges.
The metric can be represented using the formula as follows.
V(G) = e − n + 2p
- e = number of edges in the flow graph
- n = number of nodes in the flow graph
- p = number of nodes that have exit points
In a binary context, it can also be represented using the following formula.
V(G) = p + 1
- p = number of predicate nodes (= nodes that contain a condition)
This basically means that the cyclomatic complexity equals the amount of decisions plus one in a binary context. Or, in other words, it’s the amount of IF/ELSE expressions and the number of paths through a program (= the amount of potential outcomes given certain conditions).
As defined before, good metrics and their measurements are supposed to be comparable. McCabe defined the following corresponding meanings for the resulting complexity numbers.
- 1–10 = structured and well written code (= low risk)
- 11–20 = complex code (= moderate risk)
- 21–50 = very complex code (= high risk)
- >50 = not testable at all (= extreme risk)
This kind of ranking allows to introduce the following rule of thumb for development.
The lower a program’s cyclomatic complexity, the lower is the risk to modify it and the easier it is to understand.
Cyclomatic complexity applied to CSS
You might claim that CSS doesn’t have any logic and that there is no control flow. Well, how are we supposed to calculate the number of linearly independent paths if there aren’t any at all?
CSS actually does include logic: the parsing of selectors within browsers. Therefore, applied to CSS, the calculation of the cyclomatic complexity equals the amount of decisions a browser has to make before it can or can’t style something.
Again, this allows to introduce a rule of thumb for development.
Every part of a CSS selector is an IF statement. The more IF statements a selector contains, the greater is the selector’s cyclomatic complexity.
In order to illustrate these IF statements, it makes sense to think of CSS selectors as »subjects« and »conditions« while the subject represents what we actually care about and the conditions represent needless complexity[4].
The extensive selector mentioned before…
.column-wide .asset-list-box-hp-special ul li div.video-pic div.image-buttons-panel a span.button.btn-video-text
…may be divided into .btn-video-text as its subject and .column-wide .asset-list-box-hp-special ul li div.video-pic div.image-buttons-panel a span.button as its (unnecessary) conditions. These conditions are equivalent to the amount of decisions a browser has to make and thus the amount of IF statements required to calculate the cyclomatic complexity.
Examples for cyclomatic complexity applied to CSS
Now let’s have a look at three different kinds of selectors, their control flow, and their cyclomatic complexity calculation.
a#content.active > div::first-line [data-content]
This selector is neither super bad nor perfect but very likely within large projects following sophisticated product requirements.
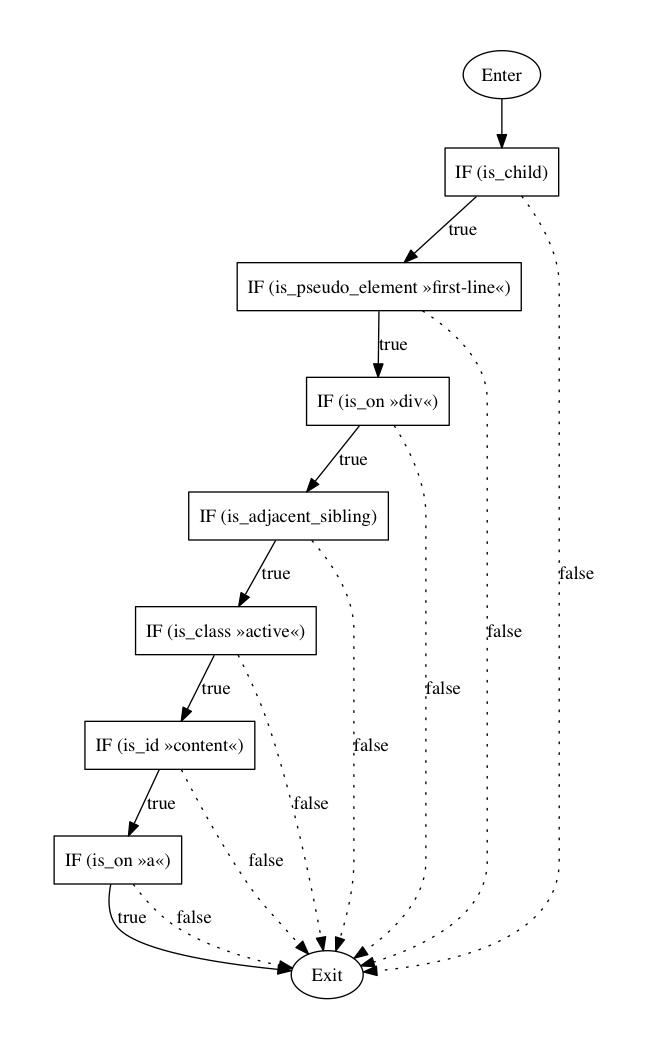
- e = 15 (number of edges)
- n = 9 (number of nodes)
- p = 1 (number of nodes that have exit points)
V(G) = e − n + 2p = 15 − 9 + 2 × 1 = 8
.column-wide .asset-list-box-hp-special ul li div.video-pic div.image-buttons-panel a span.button.btn-video-text
This selector is, as mentioned before, very extensive and definitively hard to understand or maintain. I guess we agree upon this being the worst case.
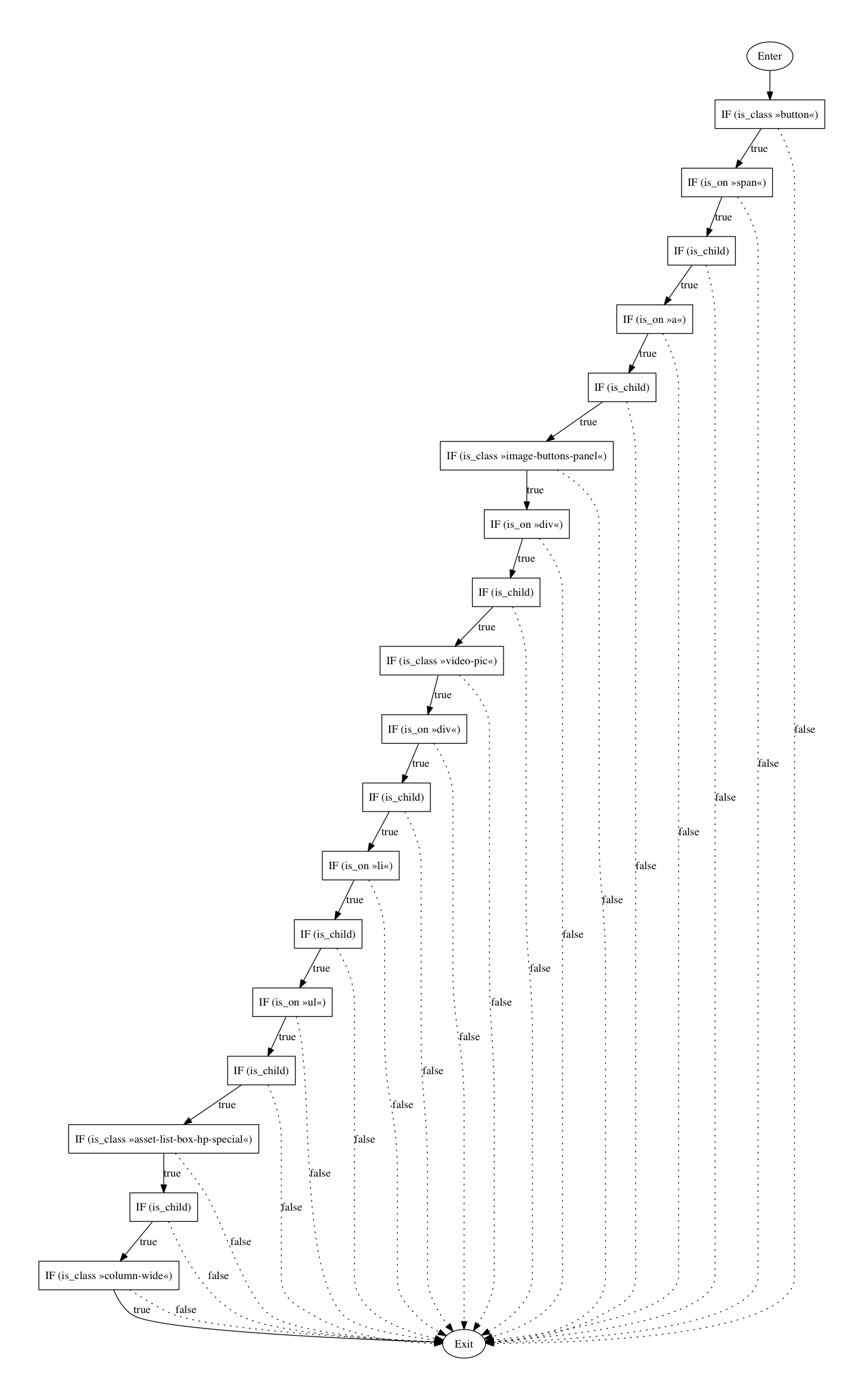
- e = 37 (number of edges)
- n = 20 (number of nodes)
- p = 1 (number of nodes that have exit points)
V(G) = e − n + 2p = 37 − 20 + 2 × 1 = 19
.sidebar-publisher__row--more
This selector follows the BEM methodology and consists of a single class (i.e. a subject without any further conditions). I guess we agree upon this being the best case.
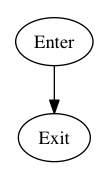
- e = 1 (number of edges)
- n = 2 (number of nodes)
- p = 1 (number of nodes that have exit points)
V(G) = e − n + 2p = 1 − 2 + 2 × 1 = 1
Halstead complexity measures
The »Halstead complexity measures« are software metrics introduced by Maurice H. Halstead in 1977[5]. These metrics reflect the code independent of its execution and are therefore computed statically from the code as well. Halstead’s goal was to identify measurable properties of software, and the relations between them.
Halstead’s measurable properties are based on the following four basic metrics while »operators« represent keywords (e.g. if, (, ), {, }) and »operands« are equal to identifiers (e.g. foo, bar, 123).
- η1 = number of unique operators
- η2 = number of unique operands
- N1 = total number of operators
- N2 = total number of operands
From these numbers, several measures can be calculated as follows.
- Program vocabulary: η = η1 + η2
- Program length: N = N1 + N2
- Volume: V = N × log2 η
- Difficulty to understand: D = η1 × η2
- Effort to understand: E = D × V
Halstead Metrics applied to CSS
Again, the question that arises is whether these measures of traditional software development can be adapted to CSS.
a#content.active > div::first-line [data-content]
This selector (respectively the amount of decisions a browser has to make before while parsing it) may be represented using the following pseudo code.
if (is_child()) {
if (is_pseudo_element('first-line')) {
if (is_on('div')) {
if (is_adjacent_sibling()) {
if (is_class('active')) {
if (is_id('content')) {
if (is_on('a')) {
…
}
}
}
}
}
}
}
When interpreting this pseudo code as a sequence of tokens, we’re able to classify each token to be either an operator or an operand as follows.
- Unique operators =
if,(,),{,} - Unique operands =
is_child,is_pseudo_element,first-line,is_on,div,is_adjacent_sibling,is_class,active,is_id,content,a
This classification defines the basic four quantities as follows.
- η1 = number of unique operators = 5
- η2 = number of unique operands = 11
- N1 = total number of operators = 49
- N2 = total number of operands = 12
Now the other Halstead measures/features are derived from these numbers with the aforementioned formulas.
- Vocabulary: η = η1 + η2 = 16
- Length: N = N1 + N2 = 61
- Volume: V = N × log2 η = 244
- Difficulty: D = η1 × η2 = 55
- Effort: E = D × V = 13420
CSSplexity & HalCSStead
In order to simplify all these calculations, I developed two tools called cssplexity and halcsstead. cssplexity-cli allows you to get started immediately. cssplexity-visualization allows you to create control flow diagrams of CSS selectors as used within this post.
Awesome. And now?
Calculating all these numbers is one thing. Getting a feeling for what the numbers are telling is another one. The general problem with measurement values is the qualitative interpretation of the numbers and acting/improving as a consequence. Metrics always have to be adjusted to their field of application. There are no universal standards. Therefore define your own set of metrics and their limits for your project and keep in mind that metrics are no replacement for revisions, tests, or verifications.
It’s vital for every kind of project and indispensable for frontend development in general that the complexity of product requirements is discussed, architectural decisions are made cautious, pair programming is used, non-obvious code is commented/documented, and code reviews are done regularly. Reviewing and optimizing CSS doesn’t end with the go-live of a product, but should be done throughout the product’s life cycle for keeping the site/application maneuverable.
The following rules of thumb are supposed to be kept in mind by every developer when writing CSS (regardless of whether it’s plain CSS or using a pre-processor).
- Each time you qualify or nest, you’re appending another IF statement. Always keep these IFs in mind and your selectors reasonable.
- Keep your (cyclomatic) complexity to a minimum. Use tools like CSSplexity, HalCSStead, Parker, or analyze-css to get metrics about your selectors.
- If you don’t really need nesting, avoid it. From time to time nesting in CSS is necessary. Most of the time it isn’t.
- Think about your selectors from the right side of life. Start with the subject, the piece you know you want, and append as little additional CSS conditions as possible in order to reach a correct match.
- Prevent hacks on the selector intent. Make sure you’re writing the CSS selectors you actually intend, not the ones that simply happen to work.