Basically, it comes down to the difference between »concrete syntax« and »abstract syntax«.
- Concrete syntax: derived tree which contains elements that are only necessary to recognize the structure
- Abstract syntax: derived tree which contains an abstraction of elements that aren’t essential for semantics
It’s »concrete« because the structure is a grammatical copy of the code/text, token by token, just in a tree format.
An AST only contains information that is related to analyzing the source code/text and ignores any kind of extra syntactic information used for parsing the code/text.
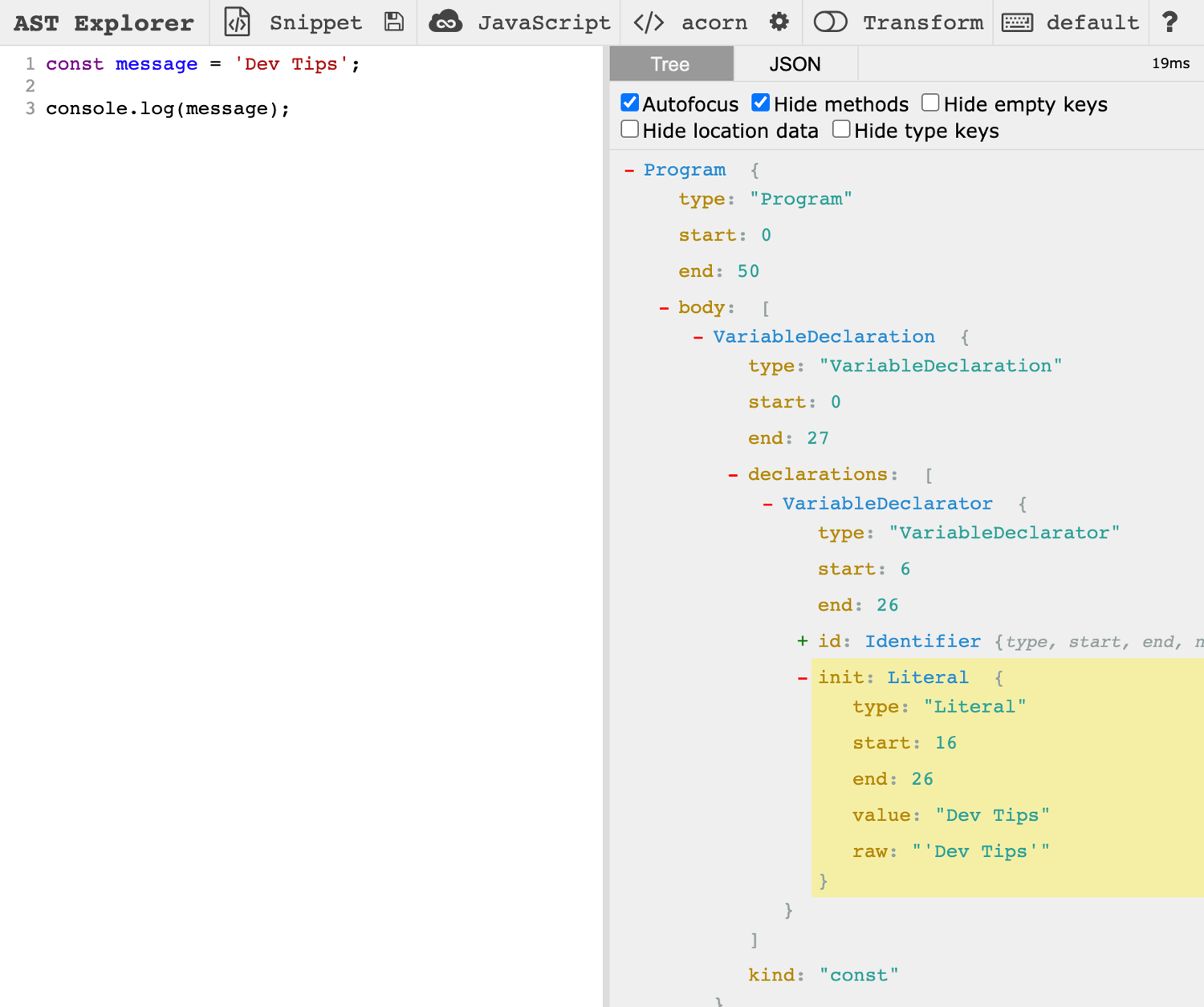
It’s a figurative representation of a code, allowing to understand the structure of a code and thus its elements and showing the relationship between the individual elements/parts. We can then query it the same way we query DOM elements in JavaScript with querySelectorAll, for example. This allows compilers/transpilers (e.g. Babel) to »understand« source code and apply specific transformations to it accordingly.
Usually, ASTs are defined in a specific standard/specification for each programming language. For example, the JavaScript AST follows the estree/estree specification.
astexplorer.net is a great web-based tool to explore the AST representations generated by various parsers for all sorts of programming languages.